AI Integration Framework
This framework provides a set of criteria to determine if a software project is prepared for the integration of AI development agents. Its purpose is to ensure that AI-generated code enhances productivity and maintains high quality, rather than creating technical debt.
The core principle is a zero-trust mindset: treat every AI contribution as if it came from a talented but brand-new junior developer who requires clear context and strict guardrails. A project that is difficult for a human to onboard will be impossible for an AI to navigate effectively.
Pillar 1: Unbreakable Quality Gates
The project must have an automated “immune system” to reject faulty code, regardless of its origin. These gates must be non-negotiable.
1. Strict, Automated Linting & Formatting
Requirement: A single, enforced code style is applied automatically across the entire codebase.
Test: Does a git commit command fail if the code is not formatted correctly?
Metric: Linting and formatting rules are applied via a pre-commit hook that cannot be bypassed.
2. Meaningful Test Suite
Requirement: The test suite validates core business logic and user workflows through a mix of unit, integration, and end-to-end (E2E) tests.
Test: Do your tests catch regressions in critical paths like user authentication, payment processing, or core data manipulation?
Metric: Test coverage is ≥70% on critical business modules. The entire local test suite runs in under 10 minutes.
3. Mandatory CI/CD Enforcement
Requirement: A Continuous Integration (CI) pipeline automatically runs all quality gates (linting, tests, security scans) on every pull request.
Test: Is it impossible to merge a pull request if the CI pipeline fails?
Metric: The PR merge button is disabled until all checks pass. The AI agent’s PR rejection rate due to CI failures is ≤20%.
Pillar 2: AI-Navigable Context
An AI cannot guess intent. The project’s “why” and “how” must be explicit, consistent, and easy to find.
1. Centralized, Up-to-Date Documentation
Requirement: A /docs directory in the repository contains key architectural information, setup guides, and decision records.
Test: Can a new developer understand why a major architectural choice (e.g., microservices vs. monolith, GraphQL vs. REST) was made without asking anyone?
Metric: Architecture Decision Records (ADRs) exist for the top 5 most significant architectural choices.
2. Well-Defined Task Specifications
Requirement: All development tasks (e.g., tickets, issues) follow a template that includes a user story, clear acceptance criteria, and examples of inputs/outputs.
Test: Could an AI agent theoretically implement a task correctly using only the information in the ticket?
Metric: 100% of new tasks adhere to the defined template, including specifications for handling edge cases and errors.
3. Consistent and Discoverable Code Patterns
Requirement: The codebase follows uniform design patterns and conventions. Similar problems are solved in similar ways.
Test: If you look at two different API endpoints, is the structure for validation, business logic, and error handling nearly identical?
Metric: A code style guide is documented and enforced. Deviations from established patterns are actively flagged in code reviews.
Pillar 3: Frictionless & Foolproof Workflow
The process for setting up, developing, and contributing code must be simple, reproducible, and safe for both humans and AI.
1. One-Command Environment Setup
Requirement: The entire development environment, including databases and dependencies, can be built and started with a single command.
Test: Can a new developer successfully run the entire application and its test suite after running just one script (e.g., docker-compose up)?
Metric: Time from git clone to a running local environment is ≤ 15 minutes.
2. Fast, Reliable Feedback Loops
Requirement: The CI pipeline provides fast and trustworthy feedback. Developers trust it enough to rely on it before merging.
Test: Do developers wait for the CI to pass before moving on to their next task, or do they ignore it due to slowness or flakiness?
Metric: CI pipeline validation for a typical PR completes in < 15 minutes. Test flakiness is < 1%.
3. AI Contribution Protocol
Requirement: A formal process exists for managing AI-generated code.
Test: Is there a rule preventing an AI agent from pushing code directly to a main or production branch?
Metric: All AI-generated PRs are tagged [AI-Agent] and require mandatory human review for security, data handling, and third-party integration changes.
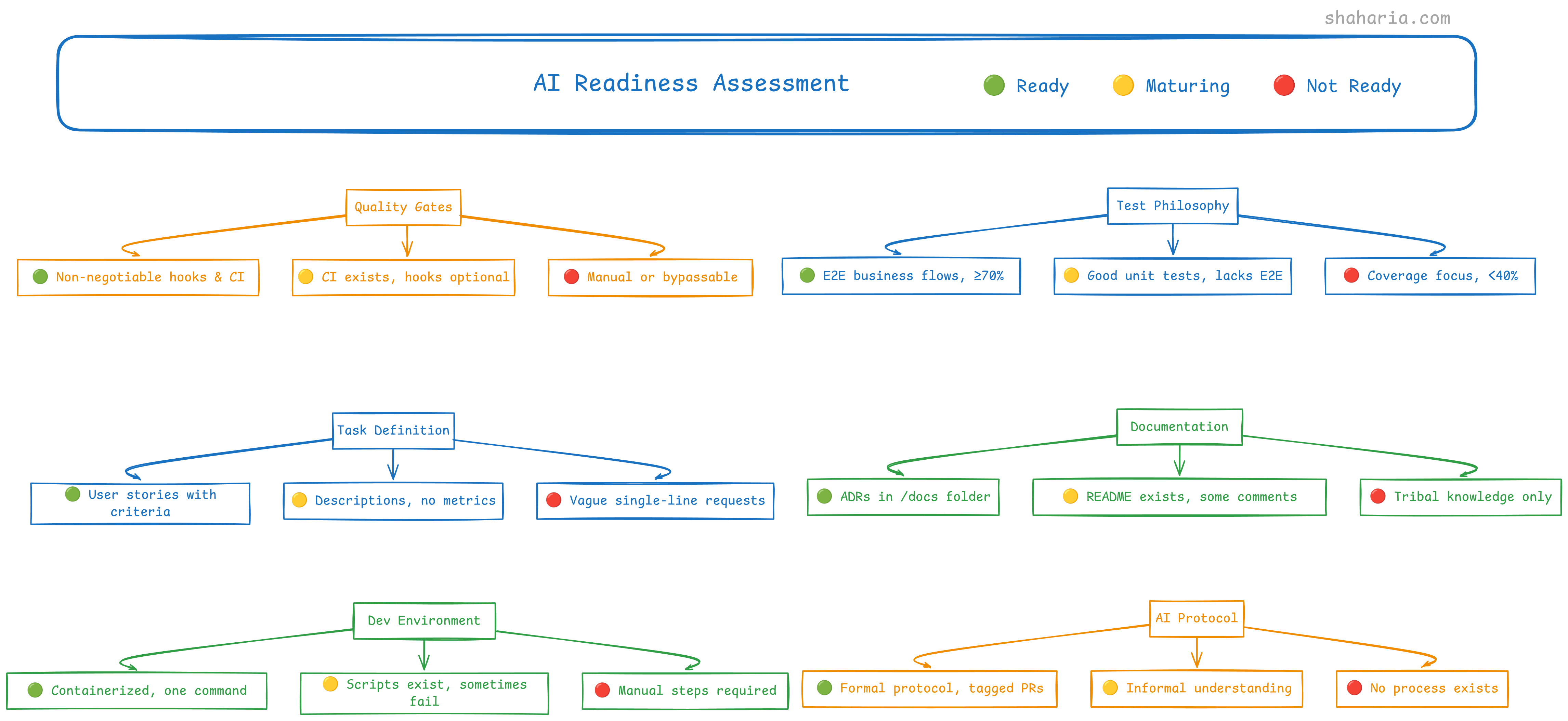
AI Readiness Scorecard
This scorecard provides a quick assessment of a project’s AI readiness, identifying areas of strength and weakness across critical development practices. It informs strategic decisions on when and how to integrate AI agents into a project workflow.
| Criterion | 🔴 Not Ready | 🟡 Maturing | 🟢 Ready |
|---|---|---|---|
| Quality Gates | Checks are manual or can be easily bypassed. | Automated checks exist in CI, but pre-commit hooks are missing or optional. | Non-negotiable pre-commit hooks and a blocking CI pipeline are mandatory for all commits. |
| Test Philosophy | Tests focus on code coverage, not business value. Coverage is <40%. | Good unit test coverage, but lacks integration/E2E tests for user workflows. | Tests are rich with E2E validation of core business flows. Coverage is ≥70% on critical paths. |
| Task Definition | Tasks are vague, single-line requests (e.g., “Fix login bug”). | Tasks have descriptions but lack clear success metrics or edge cases. | Tasks are written as user stories with explicit acceptance criteria and examples. |
| Documentation | Knowledge is tribal. No ADRs or /docs folder. | A README.md exists for setup. Some code has comments. | Key decisions are logged in ADRs. The /docs folder is a reliable source of truth. |
| Dev Environment | Setup requires many manual steps and institutional knowledge. | Setup scripts exist but are sometimes unreliable or outdated. | The entire environment is containerized and starts with one command. Setup takes <15 mins. |
| AI Protocol | No process exists. AI could theoretically push to main. | An informal understanding exists to review AI code. | A formal, documented protocol requires tagged PRs and mandatory human review for high-risk code. |
Readiness Levels & Action Plan
This section defines three readiness levels (Ready, Maturing, Not Ready) for AI agent integration based on project scores across various criteria. It also provides a clear action plan for each level, advising on when and how to introduce AI agents or to first focus on improving foundational development practices.
| Readiness Level | Status | Action Plan |
|---|---|---|
| 🟢 Ready | Scores are mostly “Ready.” The project has a strong, automated immune system. | Begin piloting AI agents. Start with low-risk, well-defined tasks like writing unit tests, refactoring code, or fixing simple bugs. Measure the impact on PR cycle time and quality. |
| 🟡 Maturing | A mix of “Maturing” and “Ready.” The foundation is there, but gaps exist in context or enforcement. | Address the gaps first. Prioritize moving all “Maturing” items to “Ready.” You can introduce low-risk AI tools like code completion (e.g., GitHub Copilot) but hold off on autonomous agents. |
| 🔴 Not Ready | One or more criteria are “Not Ready.” The project lacks fundamental safeguards. | Do not introduce AI agents. Doing so will amplify existing problems and create technical debt. Focus on improving foundational development practices first. Start by implementing non-negotiable linting and a reliable CI pipeline. |